Machine Learning Framework¶
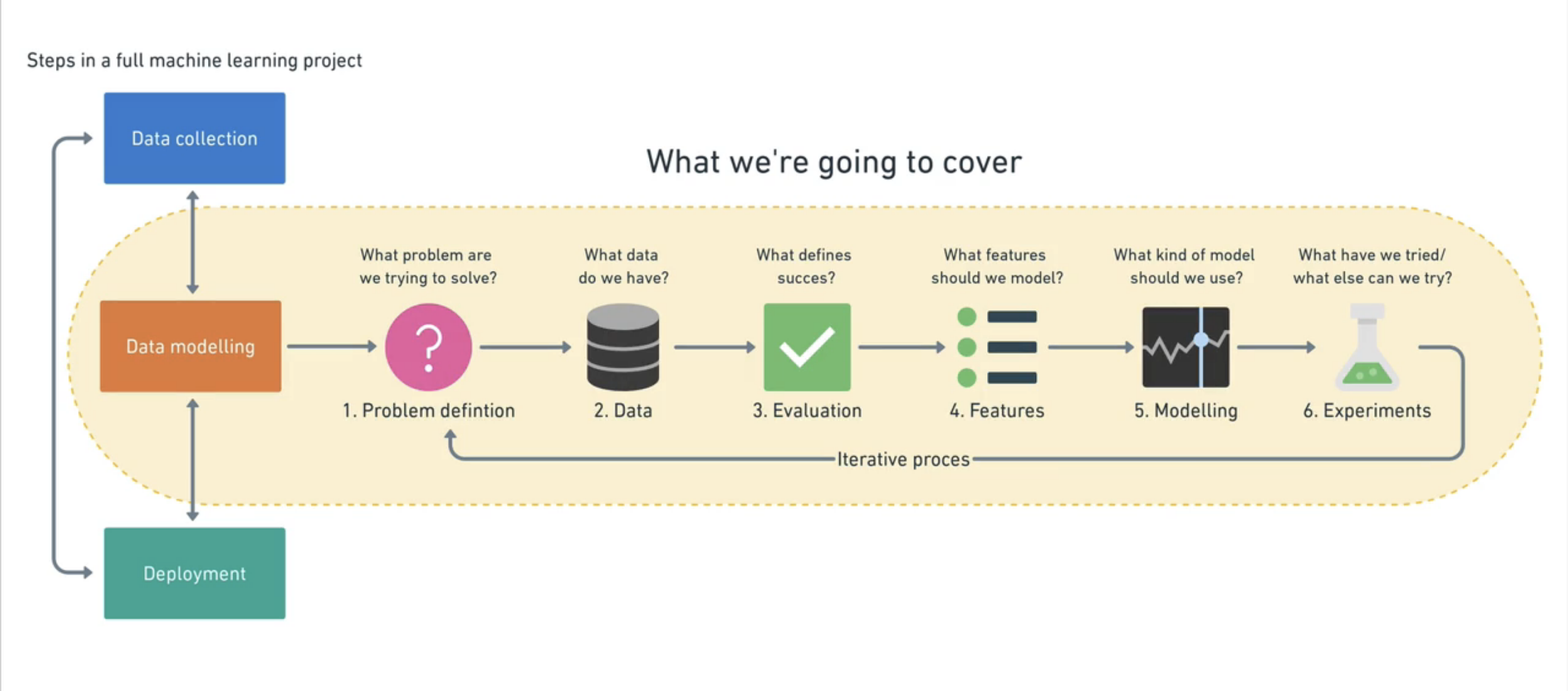
Problem Defination Basics#What is Machine Learning?¶
Know the type of the problem, which Machine Learning model will suite to solve that problem.
Data Basics#Types of Data¶
Type of data we got to solve above problem
Evaluation¶
In this step we need to define what success means to us. For a heart disease calssification our model should give 99% accuricy. For a car insurance company the model giving 95% accuracy for insurance claims is good to continue work.
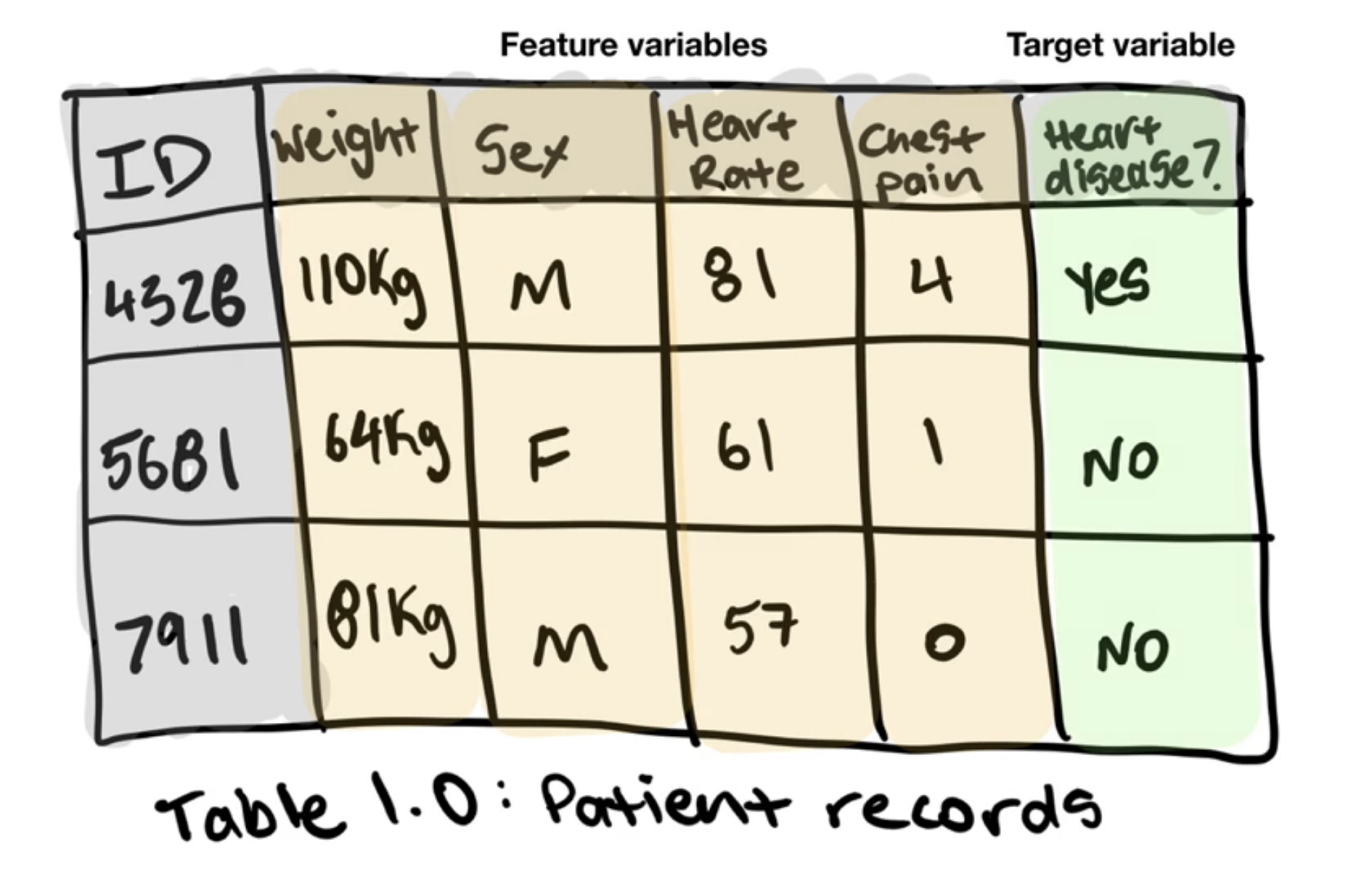
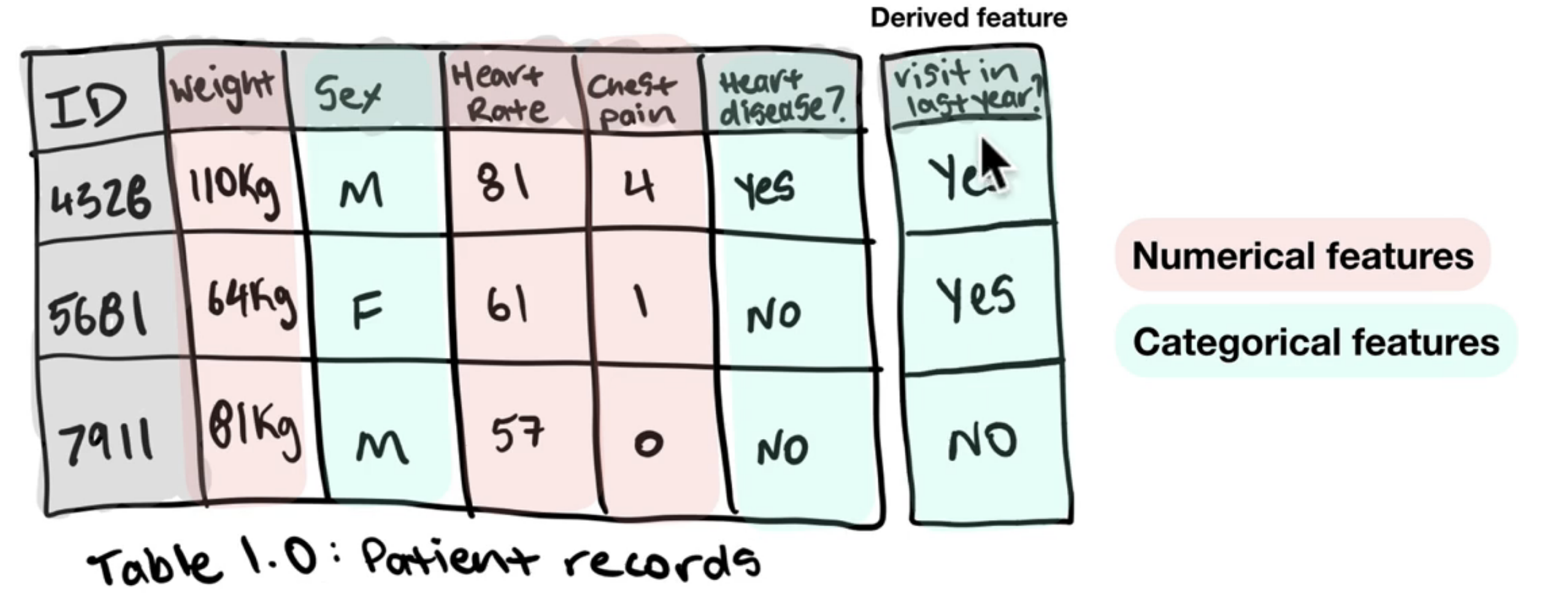
Features¶
Modelling¶
Splitting Data
70-80% for training - Use this set for model training 10-15% for validation - Use this set for model hyperparameter tuning and experimentation evaluation 10-15% for testing - Use this set for model testing and comparison
Never ever show test data to the model while training, or the results in the test phase will not be correct. as we can consider it as a cheating.
Picking the Model
It is important to pick a training model according to the problem as different problems require different type of ML models.
Note: CatBoost, dmlc Boost, Random forest algorithm works best with Structured data, while Deep Learning, Tranfer Learning, Neural Network works best with Unstructured data.
Tuning
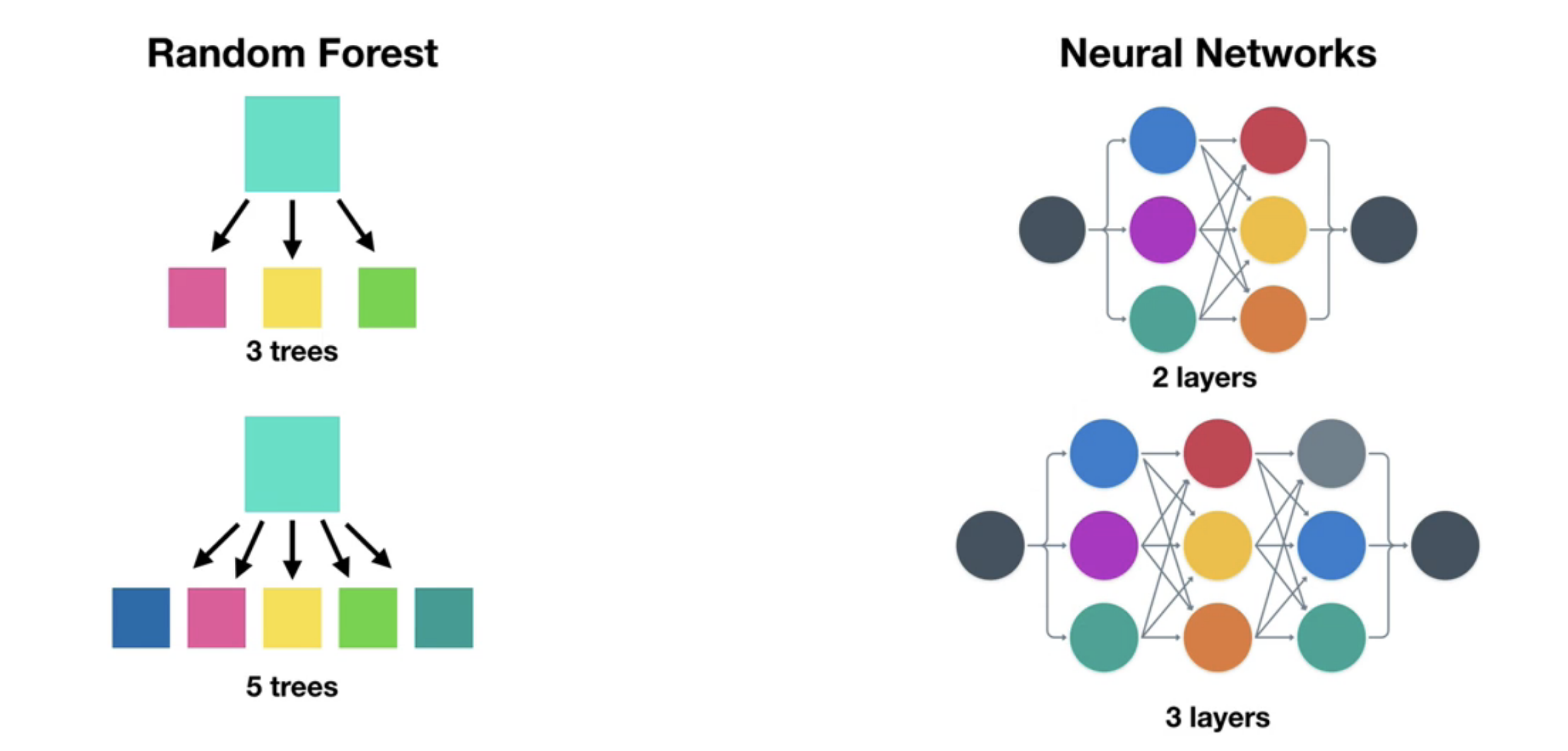
when we complete our model training on training data, it is time to improve it's accurecy further. This can be done by adding trees in Random forest or adding additional layers in Neural Network. Tuning can be place on training or validation data set.
💡
A model's first result arent it's last
Comparison
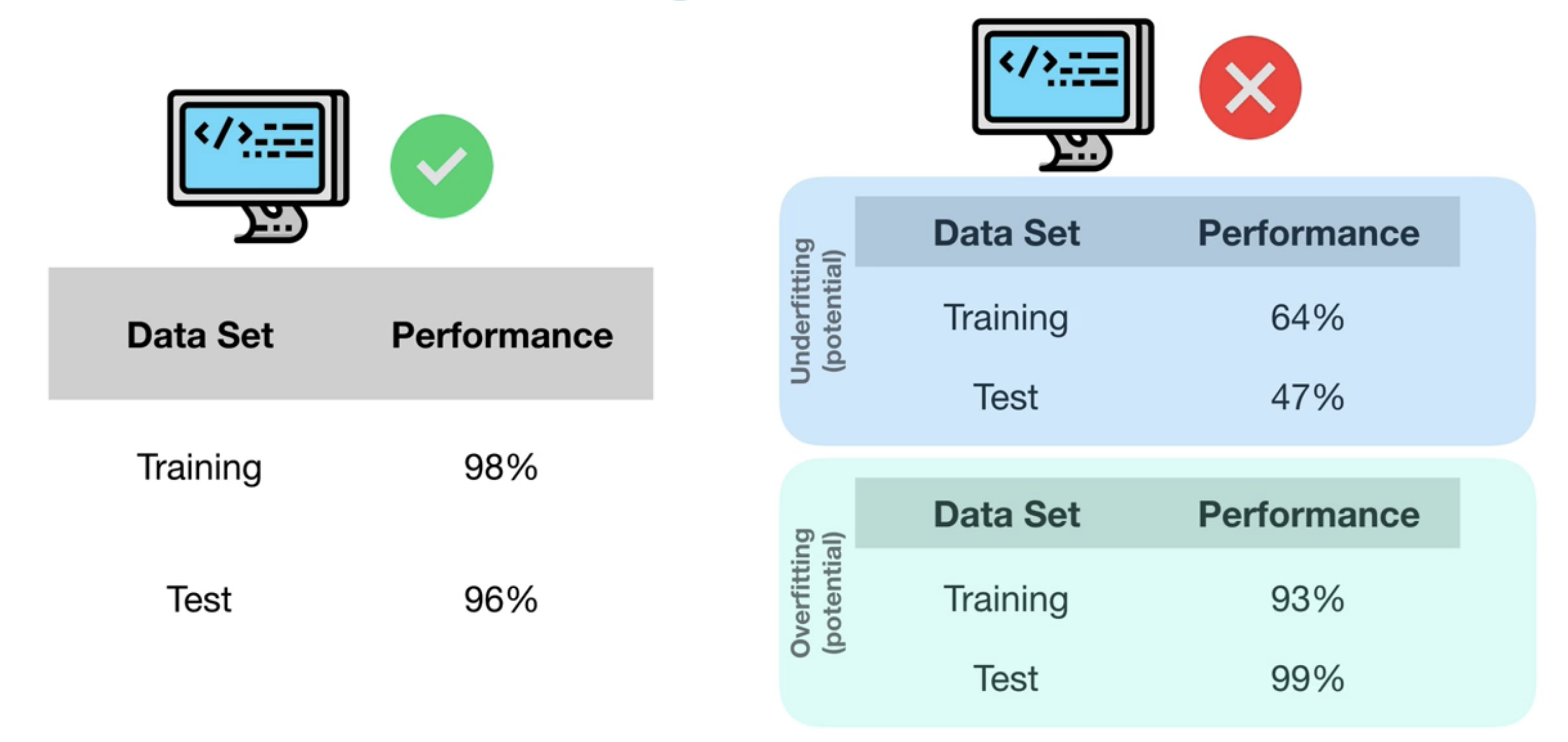
Once training is done it's time to see how our model will perform in the real world. We do this by running our model on test data. This gives a results about the accuracy of the model.
traning accuracy and test accuracy should be approximately equal.
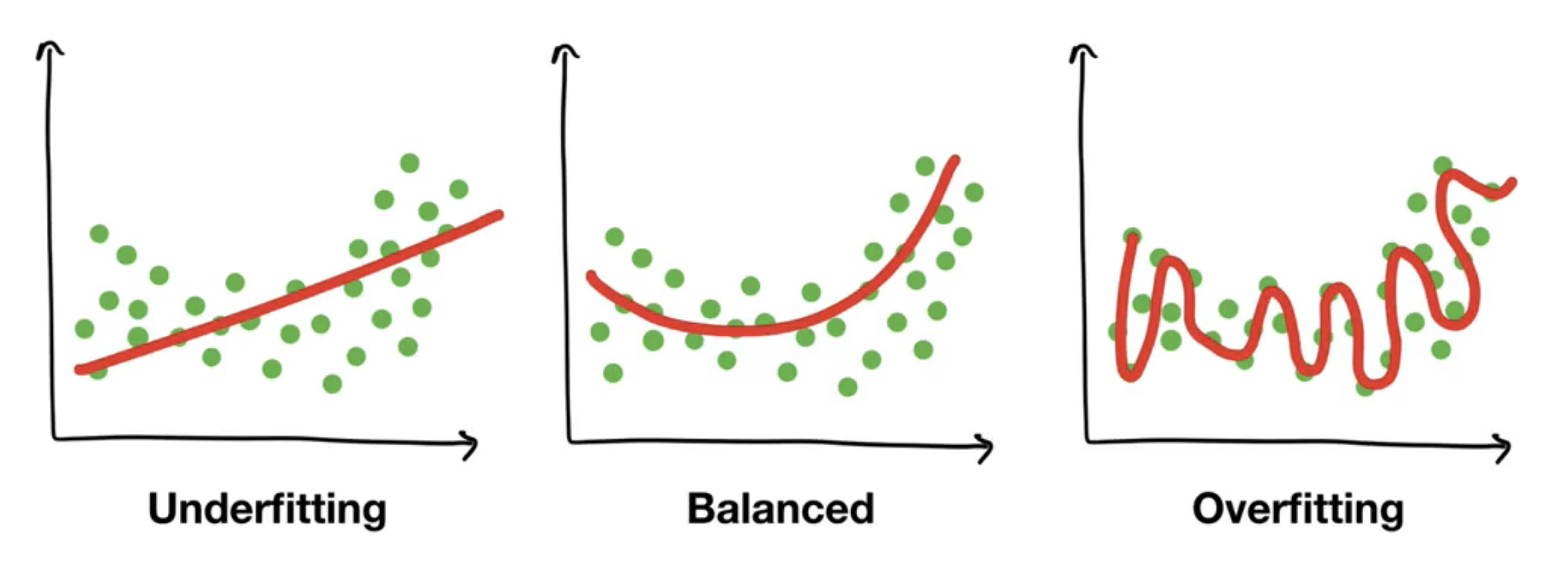
training accuracy >> test accuracy = Underfitting It happens because of data mismatch may be the features of your training data set is different than the test data.
Fixes: - Try a more advanced model - Increase model hyperparameters - Reduce amount of features - Train longer
test accuracy >> training accuracy = Overfitting This happens beause of data leaking, like some of your test data is already present in the trainig data
Keep the test data seprate at all cost
Fixes: - Collect more data - Try a less advanced model
we should avoid this two conditions.
Experiments¶
Now that our model is ready, and it's giving good outputs but still we wated to improve the performance then we will start experimenting, may be using different models, may changing the features for training or may be tweaking the input to the model.
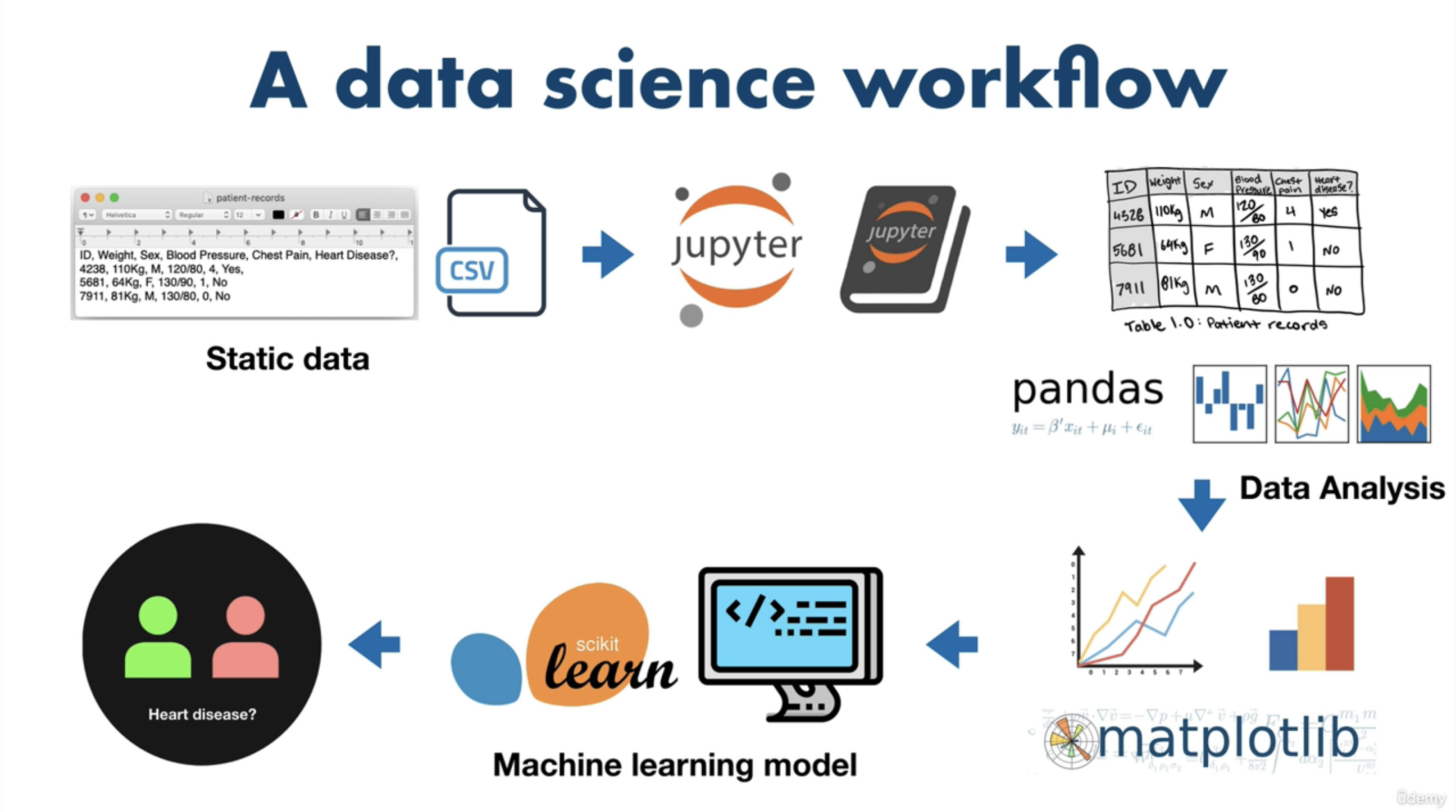
Data Science Workflow¶